SIEM Event-Level Monitoring with AI Agent Telemetry Extraction
Today, most security stacks approximate AI context extraction in familiar ways:
- PII detection/redaction (often via Microsoft Presidio), effectively repurposing DLP patterns
- Guardrails and policy checks, either fixed or customizable
- LLM-based extractors, including multi-agent setups prompted to classify or summarize content into predefined categories (e.g., "secrets," "prompt injection," "policy violation," "tool misuse")
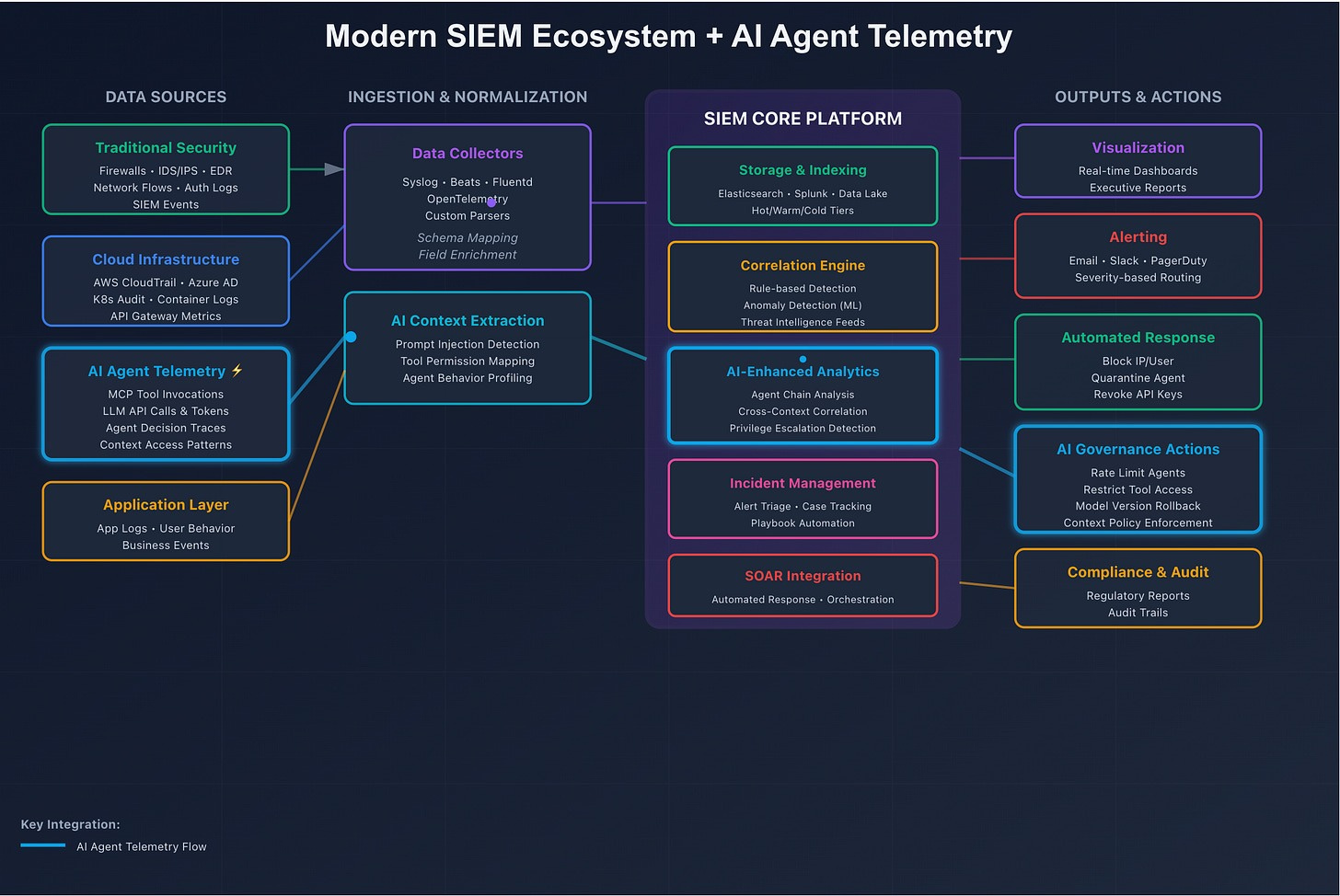
However, as evidence accumulates for adaptive, distributed, and multi-stage prompt threats, it's clear we need foundational work—not incremental extensions of yesterday's techniques.
From Events to Thoughts: What Changes
Traditional security monitoring treats events as first-class entities: logins, process spawns, network connections, file reads/writes. In agentic AI systems, that framing is no longer sufficient.
Two critical observations drive this shift:
- Events are no longer the earliest meaningful signal. Thoughts are. Many of the most important indicators happen before an OS-level event—inside language, image, or multimodal content.
- Data is code in V/LLMs. Text and images can directly elicit actions. Yet we still treat them as second-class inputs, only extracting meaning via classifiers or LLM agents constrained by precompiled taxonomies.
Why Predefined Taxonomies Are Not Enough
A common approach is to define a fixed taxonomy of threats and train/prompt extractors to map content into those buckets. That helps—but it's not sufficient.

We should allow "thought entities" to remain abstract at first. Tagging and enrichment can happen later, but the extraction layer should prioritize malicious pattern discovery—similar to how emergent behavior is learned in RL systems.
- ♟️ Adaptive attacks are a chess game. If we only look for known patterns, we lose to novelty. We need to detect interesting, security-relevant structure even when it doesn't match a predefined label.
- Multimodal attacks don't fit clean buckets. Attackers can optimize pixel-level perturbations so that a model's text output is steered toward a target, even when no explicit malicious text is present. You can't reliably "pre-bucket" that. A better extractor flags and scores the suspicious concept for downstream correlation and enrichment.
This matters even more as systems increasingly use images to carry dense context—whether through "context optical compression," screenshots, or agent access to browser-rendered pages.
Conceptual Security Monitoring: The Missing Layer
We need something analogous to a SIEM—but for abstract concepts: conceptual security monitoring.
This layer monitors and correlates:
- Extracted thought entities (from text and images)
- Tool permissions and tool-use intent
- Agent decision traces and action plans
- Cross-step and cross-session correlations (distributed in time and across systems)
The Compression Model: Scoring and Prioritization
To make conceptual monitoring practical, we need advanced scoring—a way to extract and prioritize thought concepts so they can be recomposed into a coherent threat picture.
Scoring here means:
- Ignoring irrelevant content
- Zooming in on security-relevant concepts
- Doing so without requiring a fixed taxonomy upfront
What a Useful Extraction Model Should Do
-
Detect emergent thought entities
From simple role manipulation to cognitive overload, coercion, nested overrides, and adaptive multi-stage attacks. -
Assign significance scores aligned to security objectives
For example, even under a generic policy, given instructions like: (a) encrypt data, (b) read from disk, (c) overwrite disk content—the model should prioritize these differently based on risk and context, not merely classify them. -
Support policy-driven customization
Thought scores should increase or decrease based on external policy: organization rules, tool boundaries, compliance requirements, and environment-specific risk tolerances. -
Recompose distributed fragments into a single narrative
In mosaic-style attacks, no single prompt is dangerous. The threat emerges only when fragments are assembled across time, contexts, or agents. The extracted concepts must be correlatable so downstream alerting can reach meaningful conclusions.
Example in Action
We've demonstrated this concept with atomic-level prompt injections using a proper compression model. The compression approach enables detection of malicious intent at the thought level, before it manifests as concrete actions.
For detailed analysis of how thought entities combine into complex multi-stage threats, see our multi-stage attack analysis blog.
Conclusion + Call for Partners
We need thought-level concept extraction and scoring from text and images that can be correlated back into a clear, actionable picture of AI threats—without relying on a precompiled taxonomy.
This is the direction behind Intrinsec AI's compression model and the broader idea of conceptual security monitoring.
The future of AI security will be built around conceptual security monitoring, not only event monitoring. The shift from events to thoughts represents a fundamental evolution in how we secure AI systems—one that recognizes the unique nature of AI threats and the need for security that operates at the same level of abstraction as the systems themselves.